1. Hadoop搭建
1.1 虚拟机准备
在本地VMware软件中安装三台CentOS 7的虚拟机,充当集群。安装完成后分别配置主机名和IP为如下:
1 | 192.168.10.100 cluster100 |
同时关闭所有服务器的防火墙。
1.2 Java安装
下载jdk1.8版本的Java环境,解压到/opt/module目录中。同时配置环境变量。
在/etc/profile.d/my_env.sh中添加以下内容:
1 | export JAVA_HOME=/opt/module/jdk1.8 |
刷新环境变量。然后执行java -version命令,显示Java版本表示安装成功。

1.3 Hadoop安装
下载hadoop3.1.3版本的Hadoop压缩包,解压到/opt/module目录中。同时配置环境变量。
在/etc/prodile.d/my_env.sh中添加一下内容:
1 | export HADOOP_HOME=/opt/module/hadoop3.1.3 |
刷新环境变量。然后执行hadoop version命令,显示版本表示安装成功。

1.4 Hadoop分布式运行模式
首先将上边安装的Java环境、Hadoop环境和环境变量文件同步到另外两台服务器中。可以使用scp命令发送文件和目录。
1.4.1 集群规划
| cluster100 | cluster101 | cluster102 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager |
NodeManager |
1.4.2 集群配置
集群配置主要有4个配置文件,都存储在$HADOOP_HOME/etc/hadoop目录中,分别是core-site.xml、hdfs-site.xml、yarn-site.xml和mapred-site.xml,这四个配置文件分别对应hadoop核心配置、hdfs配置、yarn配置和map
reduce配置。
1.4.2.1 核心配置
编辑core-site.xml,在<configuration></configuration>添加以下内容:
1 | <!-- 指定NameNode的地址 --> |
1.4.2.2 HDFS配置
编辑hdfs-site.xml,添加以下内容:
1 | <!-- NameNode web端访问地址--> |
1.4.2.3 YARN配置
编辑yarn-site.xml,添加以下内容:
1 | <!-- 指定MR走shuffle --> |
1.4.2.4 MapReduce配置
编辑mapred-site.xml,添加以下内容:
1 | <!-- 指定MapReduce程序运行在Yarn上 --> |
1.4.2.5 节点配置
编辑$HADOOP_HOME/etc/hadoop目录下的workers文件,把所有节点添加至文件中:
1 | cluster100 |
注意:该文件中不得有空行,每行末尾不允许有空格
1.4.2.6 分发配置
将配置好的文件分发到其他服务器(cluster101 cluster102)。
1.4.3 集群启动
如果是第一次启动,需要在NameNode所在节点(cluster100)格式化NameNode。执行命令hdfs namenode -format格式化。

打印该日志信息表示格式化成功。
hdfs启动
使用
$HADOOP_HOME/sbin/start-dfs.sh启动hdfs,由于配置了环境变量,也可以直接使用start-dfs.sh命令。打印出以下信息表示启动成功。

然后输入
jps,查看正在运行的进程。
可以看到
DataNode和NameNode都启动了。在
cluster102中也查看进程,可以看到SecondNameNode也启动了,符合最开始的规划。
启动Yarn
设计的
Yarn需要配置在cluster101中,所以需要在cluster101中启动yarn。使用命令start-yarn.sh启动。启动后使用
jps查看进程。
可以看到
ResourceManager启动了。查看信息
进入
192.168.10.100:9870查看HDFS的相关信息。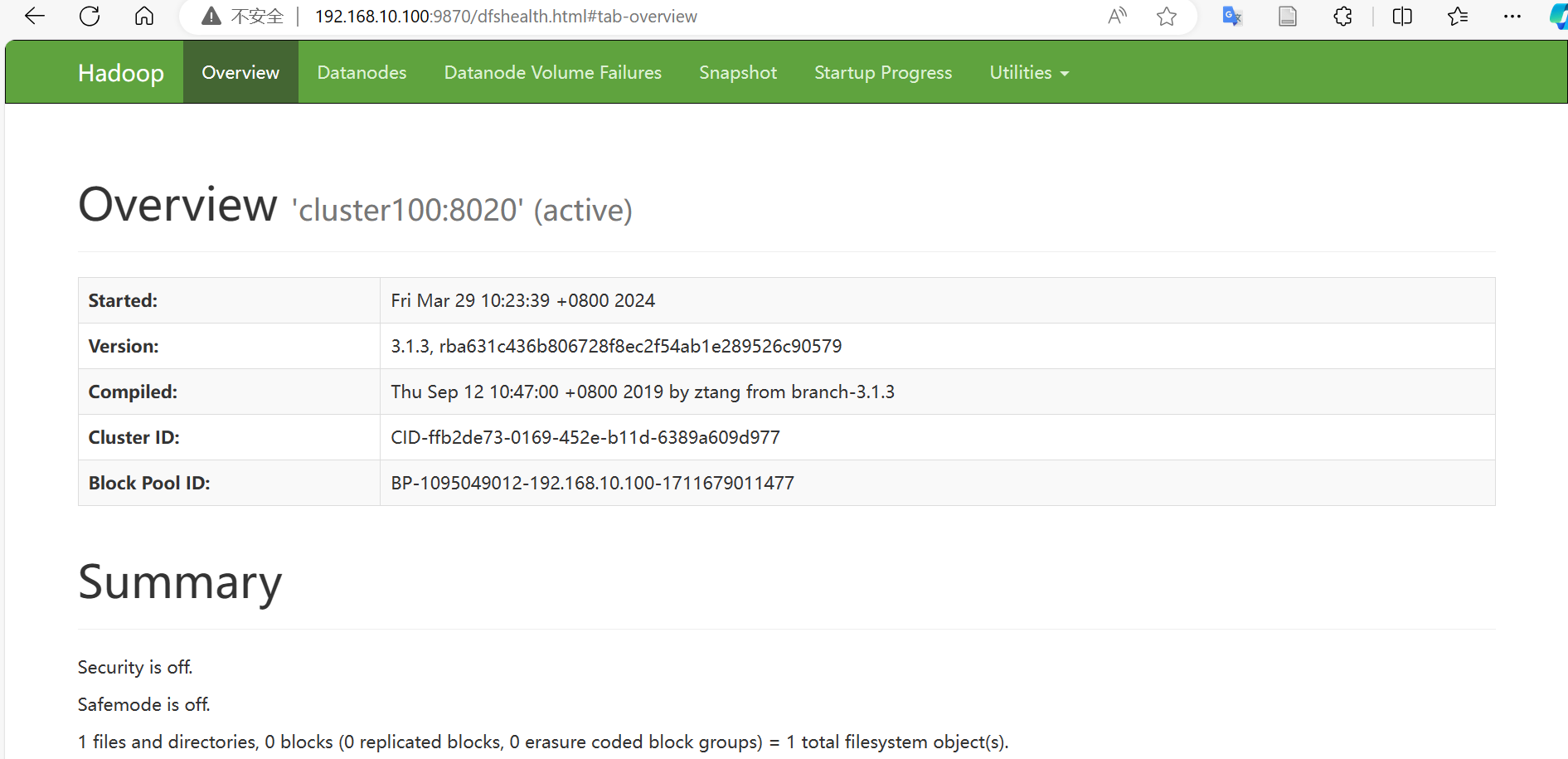
进入
192.168.10.101:8088查看Yarn相关信息。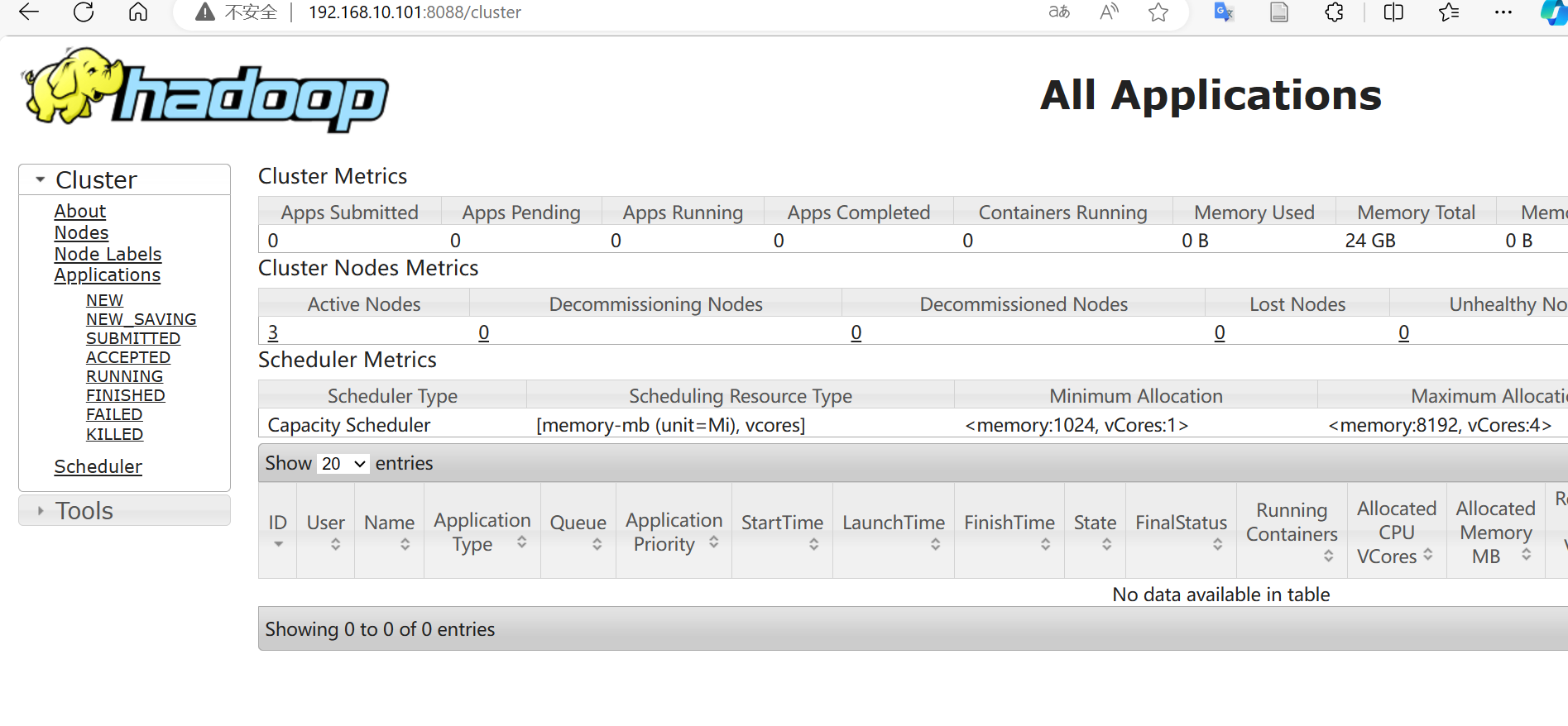
展示以上页面表明安装成功,hdfs和yarn已经成功启动。
1.4.4 配置历史服务器
该服务器可以查看程序的历史运行情况。
编辑mapred-site.xml文件,添加一下内容:
1 | <!-- 历史服务器端地址 --> |
配置好后将该配置文件分发到其他节点。然后使用命令mapred --daemon start historyserver启动历史服务器。
通过配置的端口访问Web页面,正常显示页面,证明历史服务器已经启动。
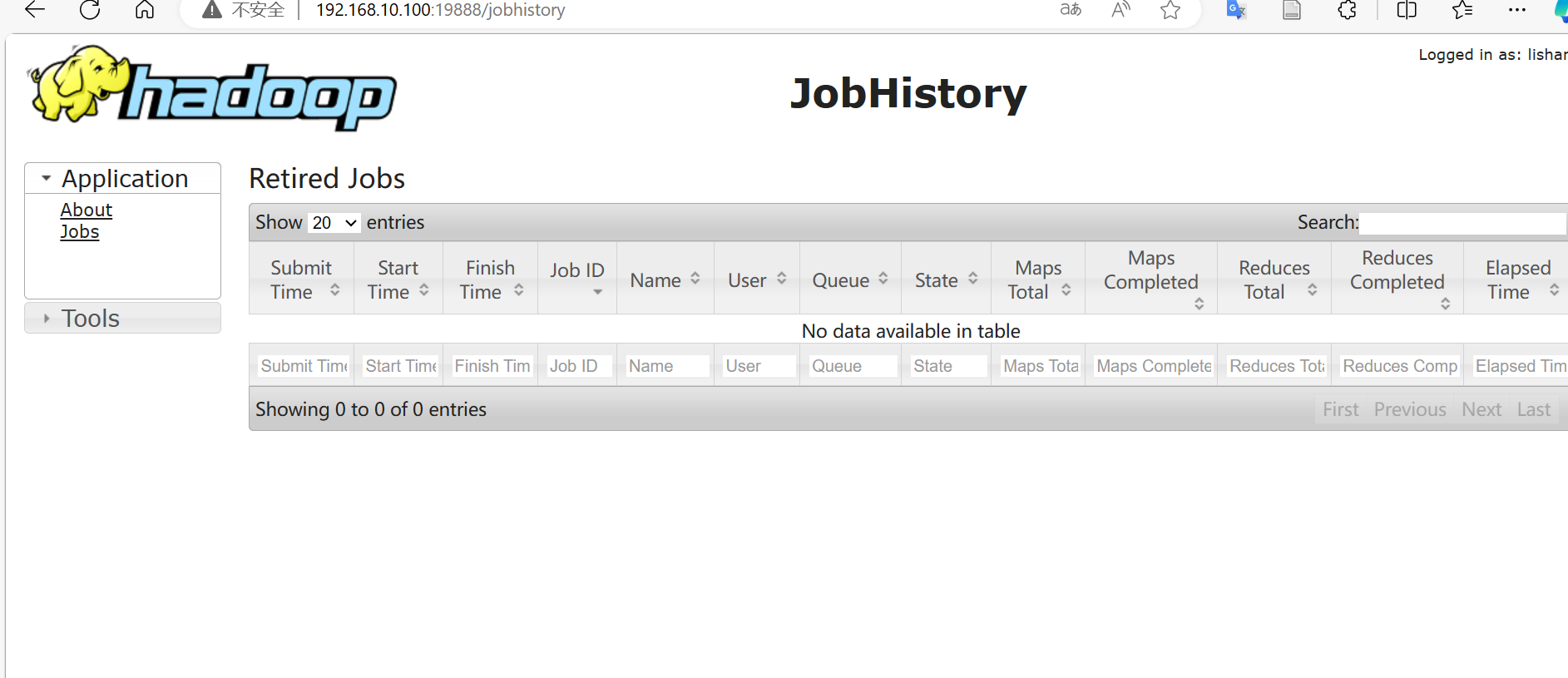
1.4.5 配置日志聚集功能
配置日志聚集可以将所有服务器的运行日志聚集到HDFS中,方便统一查看。
配置yarn-site.xml,添加以下内容:
1 | <!-- 开启日志聚集功能 --> |
将配置分发到其他节点。
注意:配置日志聚集功能,需要重新启动NodeManager、ResourceManager和HistoryServer。
需要在cluster101中使用stop-yarn.sh关闭yarn,然后使用mapred --daemon stop historyserver关闭历史服务器。
2. Zookeeper安装
2.1 下载
去官网(https://zookeeper.apache.org/)下载Zookeeper的tar包,这里选择3.5.7的版本。
采用集群部署方式安装Zookeeper,规划在三台节点都安装上Zookeeper。
首先将下载好的tar包解压到/opt/module目录中。
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
2.2 安装
配置服务器编号
在
/opt/module/zookeeper3.5.7目录中创建目录zkData,并在这个目录新建myid文件。写入内容为:
1
0
注意:不能空行,末尾不能有空格。
分发zookeeper到其他服务器。然后分别在
cluster101修改myid内容为1,cluster102修改为2。配置
zoo.cfg文件重命名
zookeeper3.5.7/conf目录下的zoo_sample.cfg为zoo.cfg。修改数据存储位置:1
dataDir=/opt/module/zookeeper3.5.7/zkData
并添加以下内容:
1
2
3
4#######################cluster##########################
server.0=cluster100:2888:3888
server.1=cluster101:2888:3888
server.2=cluster102:2888:3888server.A=B:C:D表示A号服务器的地址是B,Fllower服务器与集群中的Leader服务器使用C端口交换信息,如果集群中的Leader服务器崩溃,使用D号端口重新选举Leader。其中A即为myid中写入的编号。同步该配置文件到其他服务器。
集群启动
分别在三台节点执行
bin/zkServer.sh start。显示如下信息表示启动成功。



3. Hbase安装
3.1 下载
首先去官网下载HBase安装包,这里选择的是2.4.11的版本。
解压到/opt/module目录中,并修改名字为:hbase2.4.11。
并在/etc/profile.d/my_env.sh添加环境变量
1 | export HBASE_HOME=/opt/module/hbase2.4.11 |
3.2 安装
3.2.1 配置
配置hbase-env.sh
修改
conf/hbase-env.sh中的内容export HBASE_MANAGES_ZK=false修改hbase-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19<property>
<name>hbase.zookeeper.quorum</name>
<value>clister100,cluster101,cluster102</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://clister100:8020/hbase</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>修改regionservers
修改为如下内容:
1
2
3cluster100
cluster101
cluster102解决兼容性问题
解决hbase和hadoop的log4j兼容性问题,修改hbase的jar包使用hadoop的jar包。
1
mv /opt/module/hbase2.4.11/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar /opt/module/hbase2.4.11/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar.bak
将修改好的hbase分发到其他服务器。
3.2.2 启动
执行命令start-hbase.sh。显示一下信息启动成功。
访问192.168.10.100:16010出现hbase的页面,启动成功。

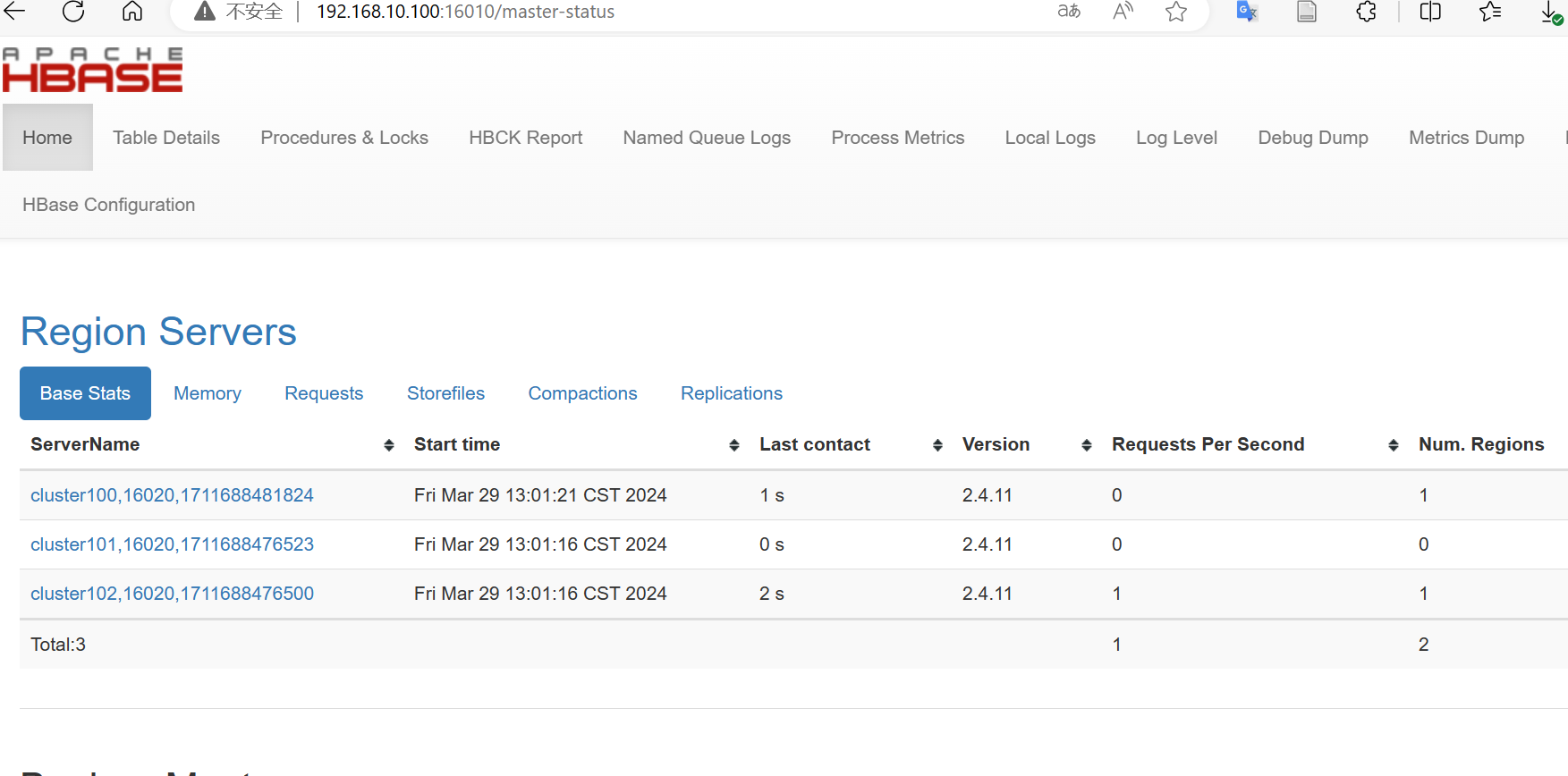
4. MySQL安装
下载mysql-xxx.tar安装包和mysql驱动jar包。
4.1 安装
解压安装包
卸载自带的mariadb
sudo rpm -qa | grep mariadb | xargs sudo rpm -e --nodeps安装MySQL依赖
1
2
3sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm安装client和server
1
2sudo rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm启动
systemctl start mysqld查看msyql密码
sudo cat /var/log/mysqld.log | grep password
4.2 配置
密码配置
个人学习可以配置一个简单的密码。
1
2set global validate_password_policy=0;
set global validate_password_length=4;设置密码验证策略为最低。
设置密码
1
set password=password("123456");
修改登录权限
1
update user set host="%" where user="root";
刷新权限
1
flush privileges;
5. Hive安装
在官网下载hvie 3.1.3版本tar包。
5.1 解压
解压tar包到/opt/module中并修改名字为hive3.1.3
1 | tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /opt/module/ |
添加环境变量
1 | export HIVE_HOME=/opt/module/hive3.1.3 |
5.2 配置元数据存储到Mysql中
登录MySQL新建元数据库
create database metastore;设置jdbc驱动
将MySQL的jdbc驱动拷贝到hive的lib目录下
cp /opt/software/mysql-connector-java-5.1.37-bin.jar /opt/module/hive3.1.3/lib/配置hvie-site.xml
在conf目录下新建
hive-site.xml文件,添加如下内容:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
<configuration>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://cluster100:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>初始化
初始化hive源数据库。
schematool -dbType mysql -initSchema -verbose如果出现报错:
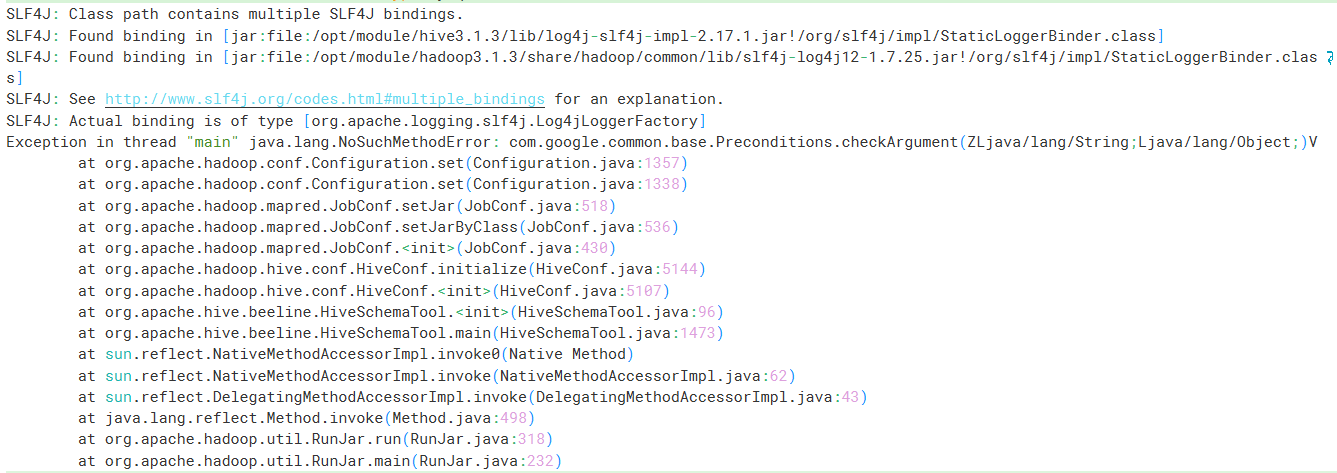
是包版本的问题,将
hadoop中相关的guava复制到hive中即可。1
2rm hive3.1.3/lib/guava-19.0.jar
cp hadoop3.1.3/share/hadoop/common/lib/guava-27.0-jre.jar hive3.1.3/lib/
打印以上信息表示初始化成功。
登录MySQL数据库,查看
metastore数据库中的所有表。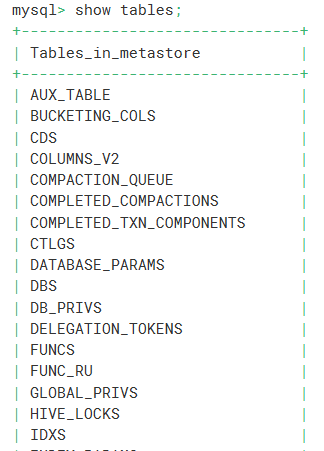
可以看到有了元数据信息。
5.3 Hive服务部署
5.3.1 hiveserver2部署
修改hadoop下的core-site.xml配置文件。增加如下配置
1 | <!--配置所有节点的lishan用户都可作为代理用户--> |
修改hive下的hive-site.xml,增加如下信息:
1 | <!-- 指定hiveserver2连接的host --> |
使用命令hive --service hiveserver2启动hiveserver2,然后在另一个终端执行beeline -u jdbc:hive2://cluster100:10000 -n lishan后看到如下信息:
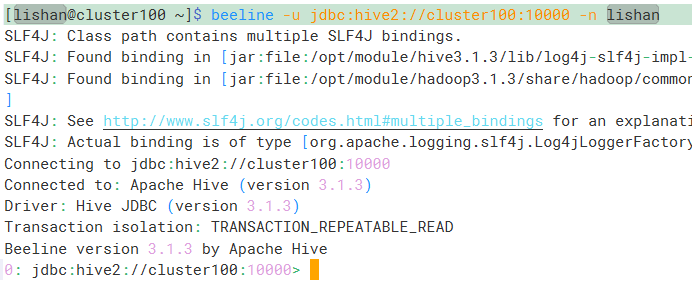
启动成功。
5.3.2 metastore服务
修改hive下的hive-site.xml,添加内容:
1 | <!-- 指定metastore服务的地址 --> |
启动metastore服务,hive --service metastore,在另一个终端启动hive,查看数据库,正常访问。
6. Spark安装
6.1 下载
这里下载的spark 3.0.0版本。
解压到/opt/module中,并修改名为:spark3.0.0。
6.2 Yarn模式配置
修改hadoop下的yarn-site.xml文件,添加内容:
1 | <!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true --> |
将spark下的conf/spark-env.sh.template重命名为spark-evn.sh并添加:
1 | export JAVA_HOME=/opt/module/jdk1.8 |
分发到所有服务器。
6.3 配置历史服务器
重命名spark目录下的mv conf/spark-defaults.conf.template conf/spark-defaults.conf。并修改该文件:
1 | spark.eventLog.enabled true |
然后在hdfs上新建该目录:hadoop fs -mkdir /directory
修改spark-env.sh,添加日志配置。
1 | export SPARK_HISTORY_OPTS=" |
修改spark-defaults.conf文件
1 | spark.yarn.historyServer.address=cluster100:18080 |
启动历史服务sbin/start-history-server.sh
7. Kafka安装
7.1下载
下载版本为:kafka 2.12-3.0.0。解压到/opt/module并修改名kafka3.0.0。
添加环境变量
1 | export KAFKA_HOME=/opt/module/kafka3.0.0 |
7.2配置
进入kafka目录,修改config/server.properties文件,修改以下内容:
1 | #broker的全局唯一编号,不能重复,只能是数字。 |
分发kafka和环境变量文件到其他服务器。修改cluster101的borker.id为1,cluster102的borker.id为2.
7.3 启动
在zookeeper集群启动的情况下启动kafka。
在每个节点上分别启动kafka。
1 | bin/kafka-server-start.sh -daemon config/server.properties |
使用jps查看进程
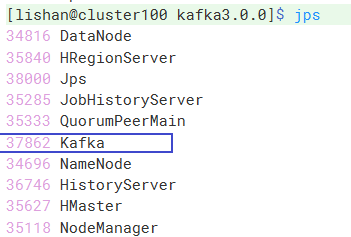
可以看到kafka已经启动了。
8. Storm安装
下载storm 1.2.4版本。并解压到/opt/module中修改名为storm1.2.4。
8.1 配置
修改conf下的storm.yaml文件。
1 | storm.zookeeper.servers: |
将storm分发到其他节点
8.2 启动
在cluster100启动:
1 | nohup /opt/module/storm1.2.4/bin/storm nimbus > /opt/module/storm1.2.4/output.log 2>&1 & |
另外两个节点启动:
1 | nohup /opt/module/storm1.2.4/bin/storm supervisor > /opt/module/storm1.2.4/output.log 2>&1 & |
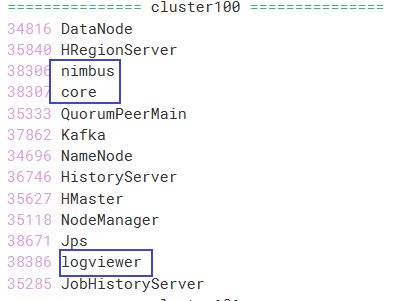
cluster100查看进程,出现core nimbus logviewer即成功。
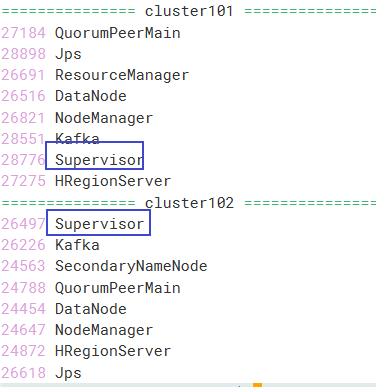
另外两个节点出现supervisor
9. Cassandra安装
下载版本为cassandra 3.11.10的版本。完成后解压到/opt/module并修改名为:cassandra3.11.10
9.1 配置
在cassandra目录下新建data commitlog saved_caches三个目录。
修改conf/cassandra.yaml文件。
1 | data_file_directories: |
9.2 启动
执行命令bin/cassandra启动。然后再开一个终端,执行命令bin/cqlsh。显示以下内容:

启动成功。
9.3 添加开机自启
vim /usr/lib/systemd/system/cassandra.service创建服务文件。
1 | [Unit] |
然后刷新服务,设置开机自启
1 | sudo systemctl daemon-reload |
10. 各框架简单操作
10.1 hadoop
hadoop基础操作查看hdfs中的文件。有两种方式。
通过UI页面查看
访问
192.168.10.100:9870/explorer.html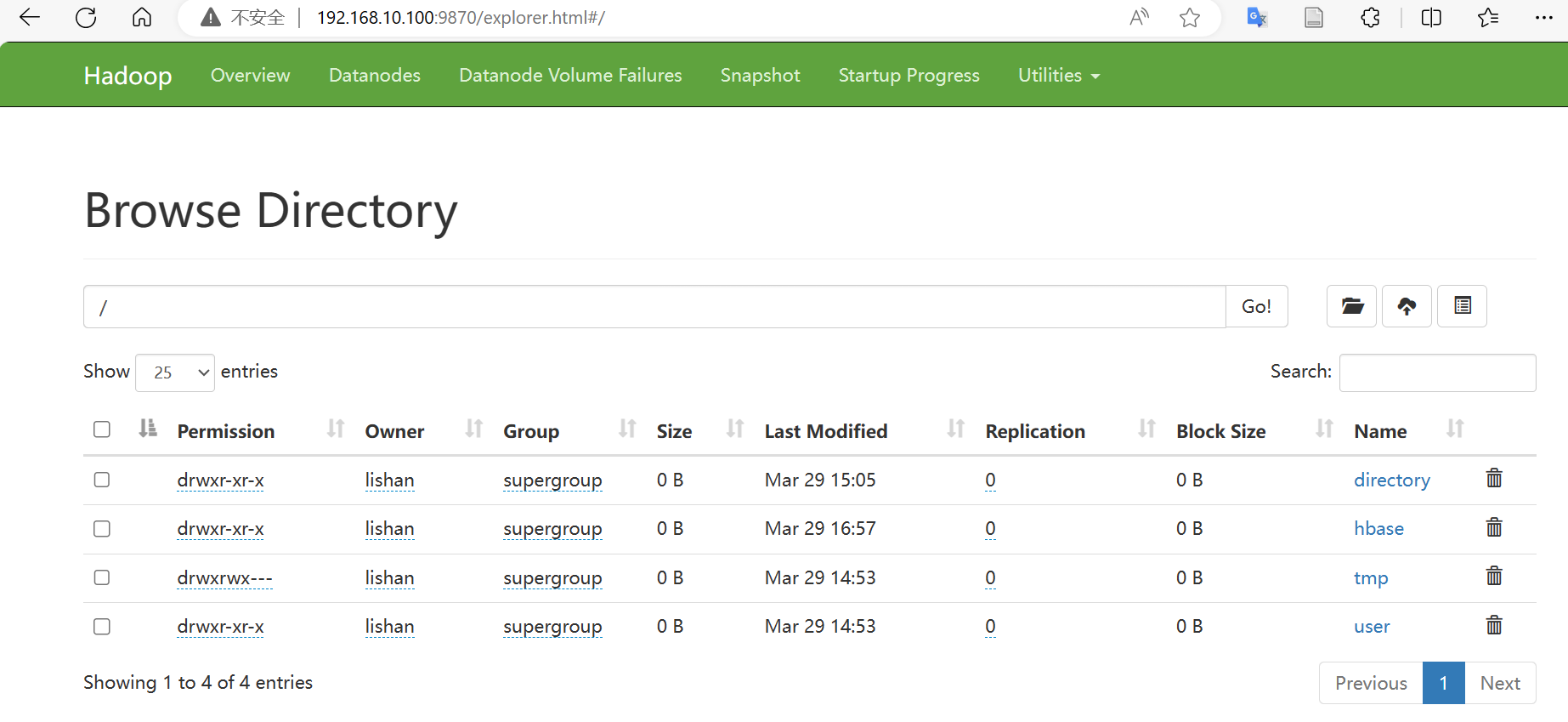
可以查看到目前hdfs中存储的文件。
通过命令查看。
使用
hadoop fs -ls查看目录。
如图,查看根目录下有哪些目录。
10.2 Zookeeper使用
使用zookeeper目录下的bin/zkServer.sh status命令可以查看到当前节点的状态。

10.3 HBase使用
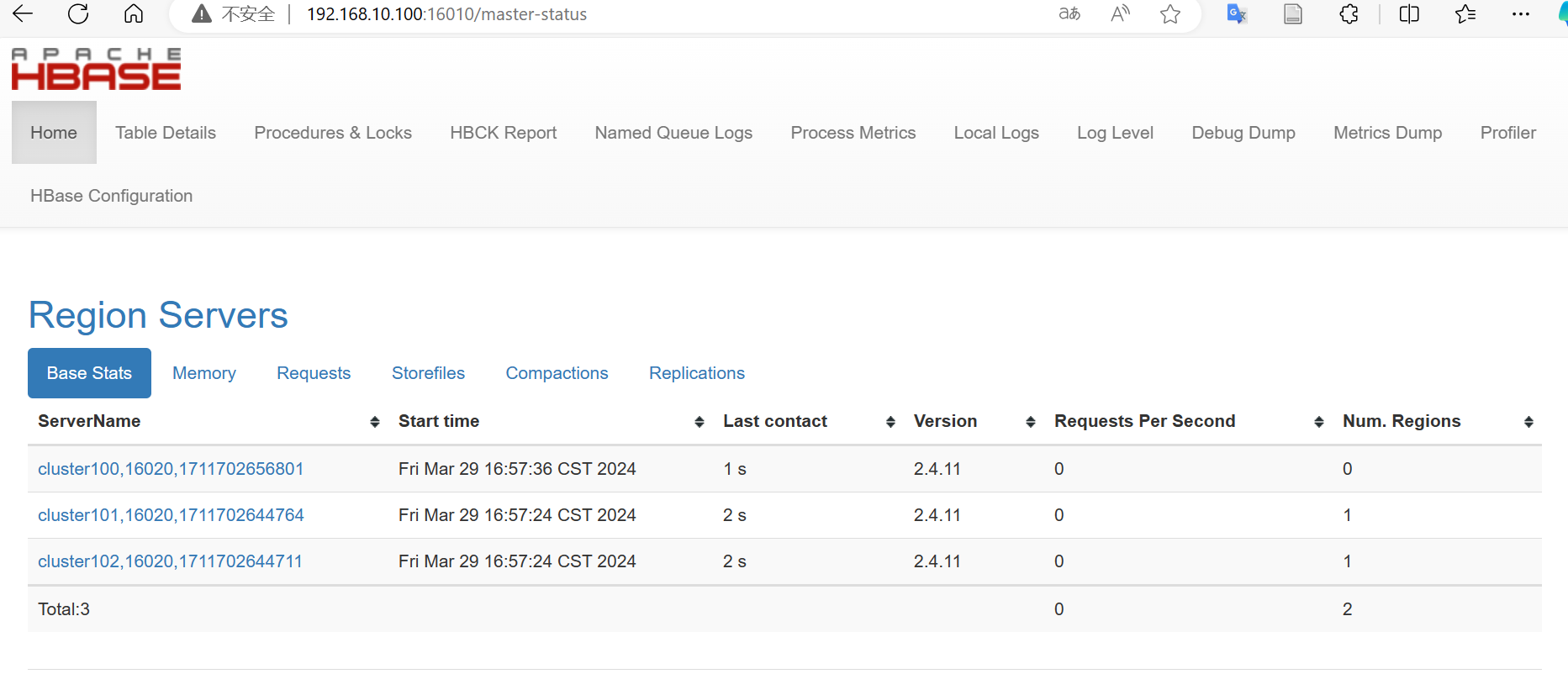
通过访问Web页面,查看信息。
10.4 Hive使用
执行命令hive进入hive cli。
创建数据库后查询。

然后访问hadoop的web页面。查看hdfs的存储数据

可以在hdfs中找到创建的test数据库。
10.5 Spark使用
进入spark目录,执行如下命令,可以使用spark默认的应用测试spark环境。
1 | bin/spark-submit \ |
运行后,可以进入yarn的页面192.168.10.101:8088,查看到当前正在运行的任务。
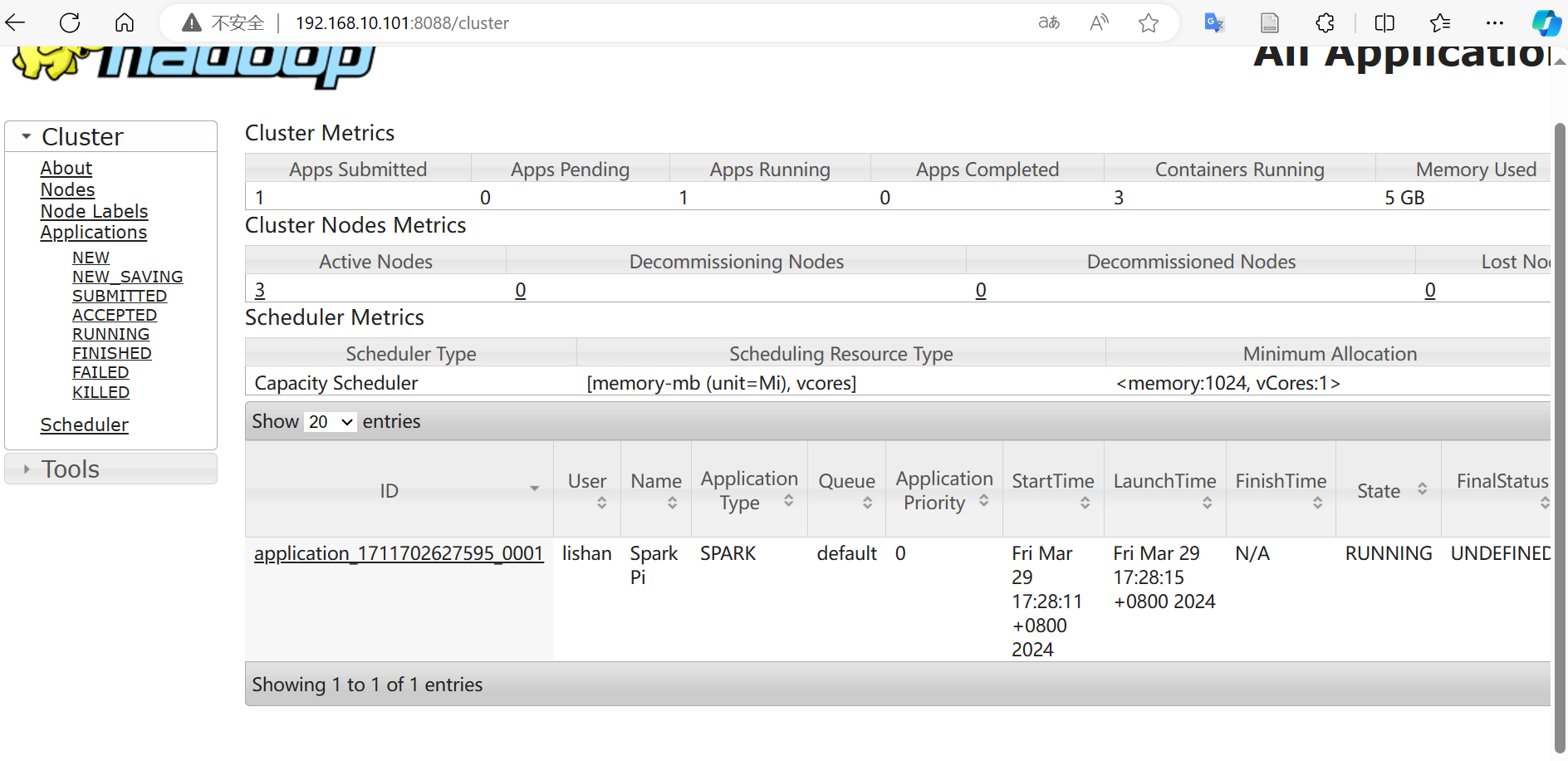
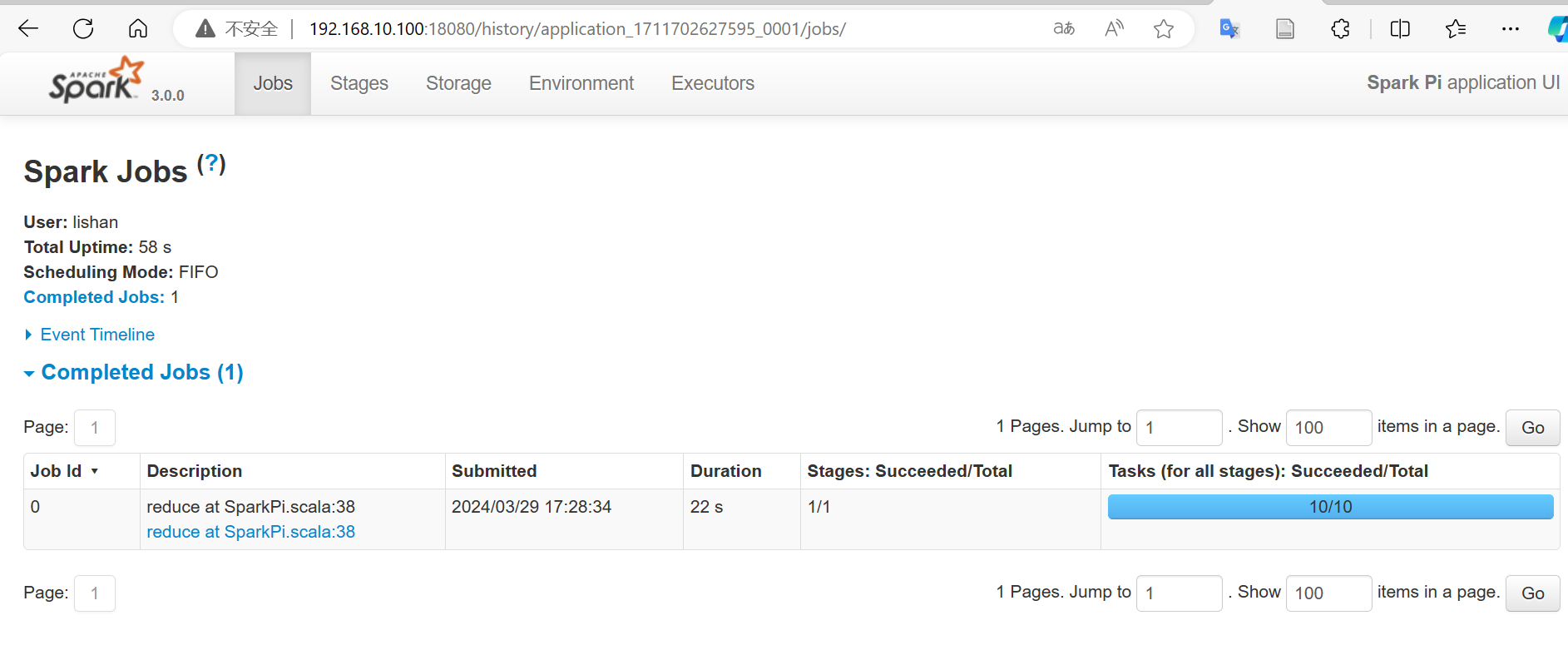
点击任务后的history可以进入到历史页面,查看到任务的历史运行日志。
10.6 Storm使用
可以访问ui页面192.168.10.100:8888查看信息。
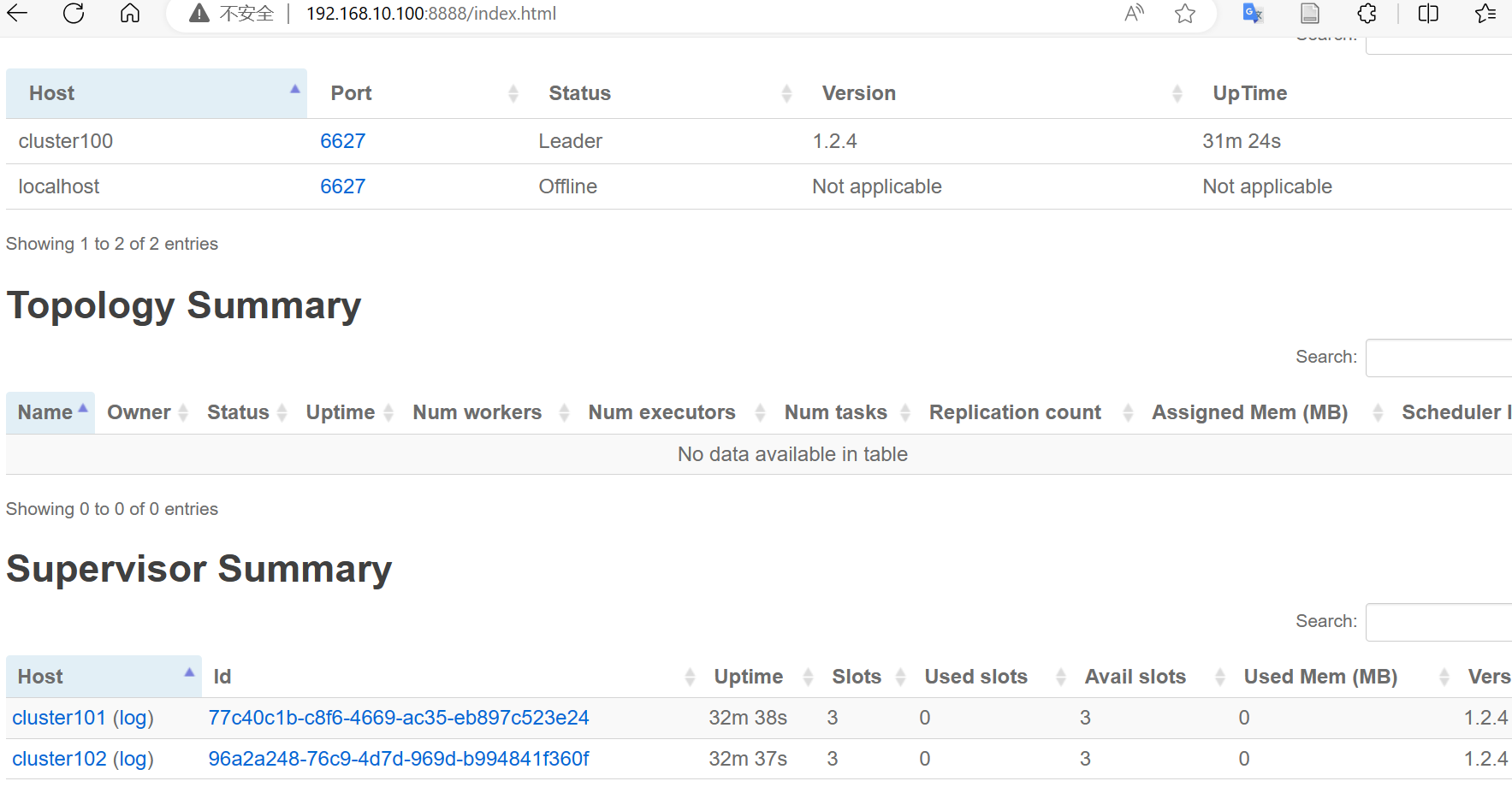
可以看到三个节点都正常运行。
11. 总结
本次实验学习了大数据集群环境的搭建,了解到了很多大数据相关的组件。和同组的同学一起学习了相关的知识,我们每个人都搭建了一遍大数据的环境,提高了动手能力。
附录
这次实验中,为了方便集群的操作,写了一些脚本,方便后续使用。(基于尚硅谷hadoop教程)
myhadoop: 用于一次性启动和关闭所有相关组件
使用样例myhadoop start myhadoop stop
1 |
|
xsync: 用于同步目录或文件到所有节点。
使用样例 xsync /opt/module/spark
1 |
|
jpsall: 查看所有节点的进程,并展示出来。
1 | for host in cluster100 cluster101 cluster102 |